Have you ever taken a look at the comments section on some of your favorite YouTube videos? Of course you have, and like me you probably had the same reaction “What the hell are they all talking about down there?”. This past weekend I decided to quickly put together a Python based analysis tool that could scrape any YouTube video for metadata as well as all the available comments. The last part of the tool would allow an user to visualize the most commonly used words within those comments in a visually appealing way. The finished application works quite well, and I hope to continue adding capabilities to the tool in the coming months.
Code: https://github.com/pseudobrilliant/youtube_analyzer
API vs. Scraping
My initial thought when starting on this project was to make a simple tool that could retrieve user data with as little pre-requisite manual setup as possible. As such I immediately discarded the notion of using the YouTube API. Yes the API would have provided the data I needed, and possibly more, with much less effort. However, I believe by first implementing a scraping tool I open a path to a further customizable way of retrieving data that goes beyond the YouTube API limitations. It is true that implementing a scraper as a first option is more involved than the API path, but the API path can easily be added to the tool as an option in the future. Also, I thought an automated web scraper that pretends to be a regular user before globbing up all the data was a pretty cool application too.
Tool Design
Primary libraries used by the tool:
- Selenium
- BeautifulSoup
- WordCloud
- PySpellChecker
The tool attempts to load and scrape any YouTube Video page through an automated selenium web driver instance. The tool uses the web driver to load a Firefox browser (visible or headless) and then save the html for post-processing. However, YouTube does not load all comments at once, it instead loads a block at a time as the user scrolls down the page. I replicated this behavior using the selenium driver, allowing the full page to load once the scroll can no longer continue. The full html should now be available to download and store for post-processing.
Next, the user can parse the scraped html source for metadata regarding the video and user comments. This source is run through the BeautifulSoup parser and then run through a custom parser process. The parser provides specialized classes for parsing both of these types of information from the video page. The resulting objects can then be output to either JSON or CSV data formats. The CSV data provides comment data in a flat format to be consume by the analyze scripts. The JSON format contains all the data for the target video in one file, to be used for future planned features.
Lastly, I implemented several analysis scripts that comb through the CSV comments, clean and process the data, and generate visualizations or further useful features. One script available allows for the detection of the most probable language used for each comment. Another script allows for the visualization of the most used words in comments through Word Clouds.

Word Clouds
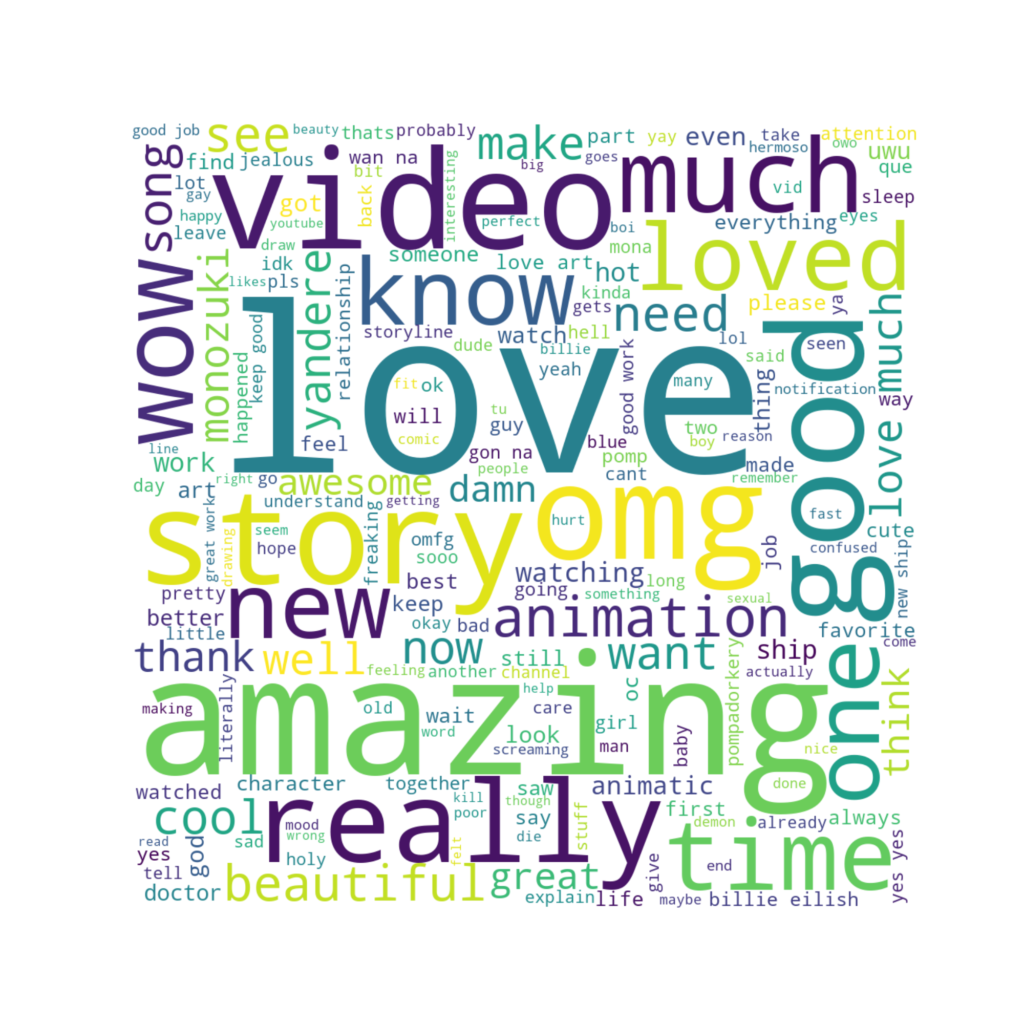
Word Clouds are great tools for showing the most used and related words in any corpus. The WordCloud library makes this capability extremely easy to implement. However, YouTube commentors do not have the same level of consideration for making my life easier. Particularly annoying is the fact that most commentors are generally attempting to convey the same thoughts, but just doing it with all sorts of misspellings. Well let me correct that, mispellings, emojies, and creative use of repeating characters (yaaaaaaaaaaayyyyyayayyyy!!).
To address this I implemented clean up scripts that will attempt to clean up the comments by: removing repeating characters (3 or more repeats), using single case, pulling apart contractions, removing unsupported unicode characters, etc. I also implemented optional spelling correction scripts, but found the results to be unstable and best left for futher experimentation.

Lastly, I implemented masked word clouds that use a base image as a template in which to depict the cloud. The masks are also analyzed for their primary colors and used to color each word as it is placed in the plot. This allows for a creative use of templates and fonts that might allow the reader to engage more with extracted content.
Use Case
Lastly, It turns out a friend is actually a rather successful animator on YouTube, which makes for a perfect use case for my new analysis tools. I took my newly created scripts and set them to the task of analyzing multiple videos on their channel. I then took related works of art to each video and used them as automated masks to further the theme of the videos. I think the end result is a form of art, from the people for the people.


Leave a Comment